どうも!リョクちゃです。
ネットサーフィンをしていると、ふと検索結果を一時的にでも
セーブしておきたいときってありませんか?
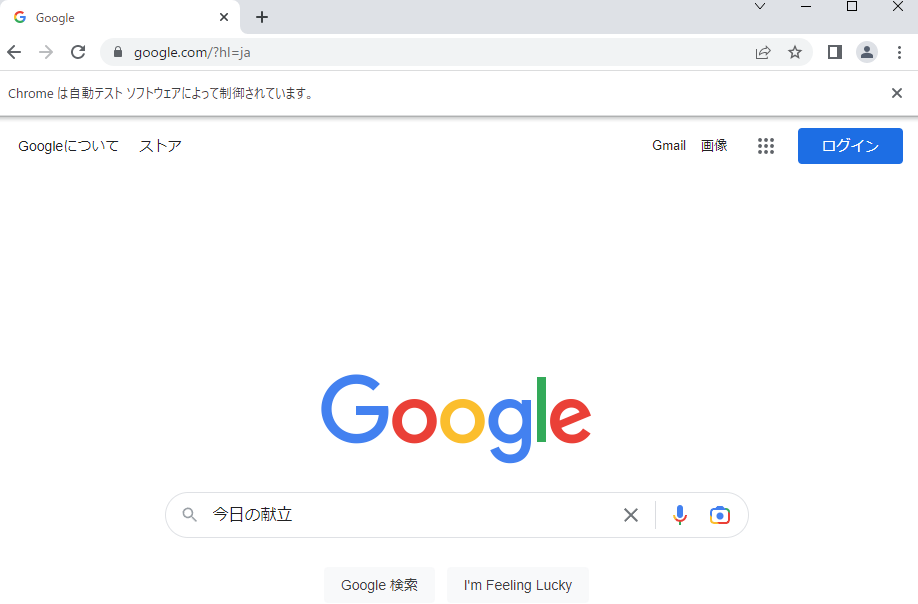
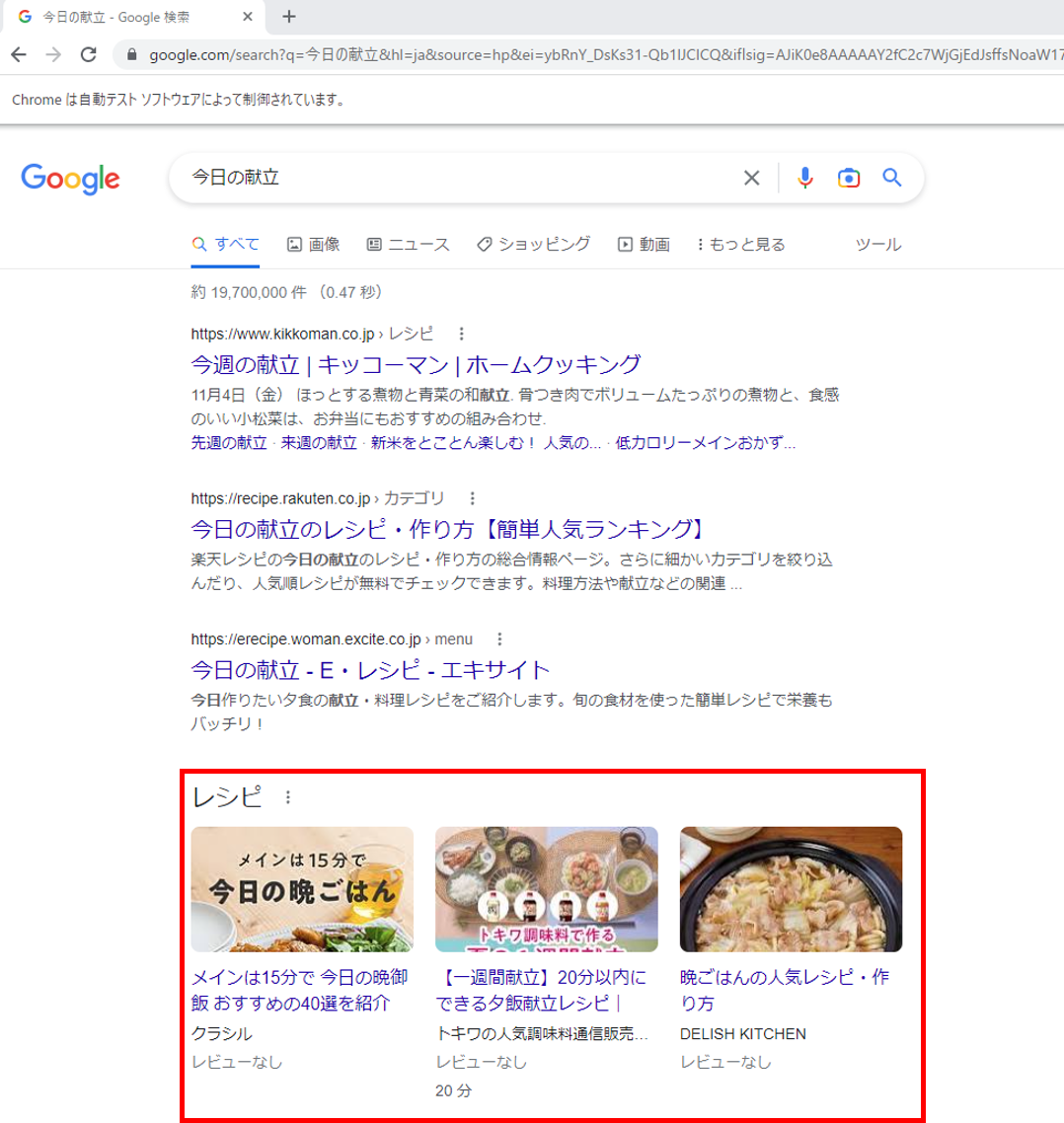
例えば、Google検索でキーワード「今日の献立」で調べた時に、
下図のような結果が得られるかと思います。

全ての結果を見るには、応える時がありませんか?
今回は、Google検索して得られた結果をPython + Seleniumで
CSVファイル形式もしくは何らかの変数に格納する方法を簡単に紹介していきます。
ちなみに前回はこちら


Seleniumに関しては、こちらを参照ください。


今回、動作環境ですが、Jupyter Notebookを使用して検証を行います。
検証程度であれば、こちらの方が早いため、活用しています。
ブラウザには、Google Chromeを使用しています。
目次
準備編:Seleniumの準備
Jupyter Notebookを起動し、Seleniumをインポートし使える形にします。
実行すると、別ウィンドウでブラウザが立ち上がるかと思います。
対象となるページのURLを開く
ブラウザが立ち上がったら、今回対象となるWebページのURLを開きます。
対象のURL:https://www.google.com/?hl=ja

上図のIn[2]でurl変数に対象のURLを代入し、In[3]で立ち上がったブラウザに対して、
url変数を渡すことで、Webページを開いています。
以下、実行後のブラウザの状態になります。
ここまでで検索をするまでの状態に整えることができました。
以降では、実際に検索をSeleniumを用いて実行し、検索結果を取得していきます。
Google検索をする
検索キーワードには、「今日の献立」としておきます。
まず、Google上で検索をするには、
- 検索ボックスの要素を取得
- 1.で取得した検索ボックスに検索したいワードを入力
- 検索ボタンの要素を取得し実行
1~3の処理を行うことで、Google検索をすることができます。
実際に、これらの処理をPythonで書いていきます。
検索ボックスの要素を取得
まず、Googleの検索ページで、検索ボックスとは何か?
これは下図の赤枠で示されるオブジェクトが検索ボックスになります。
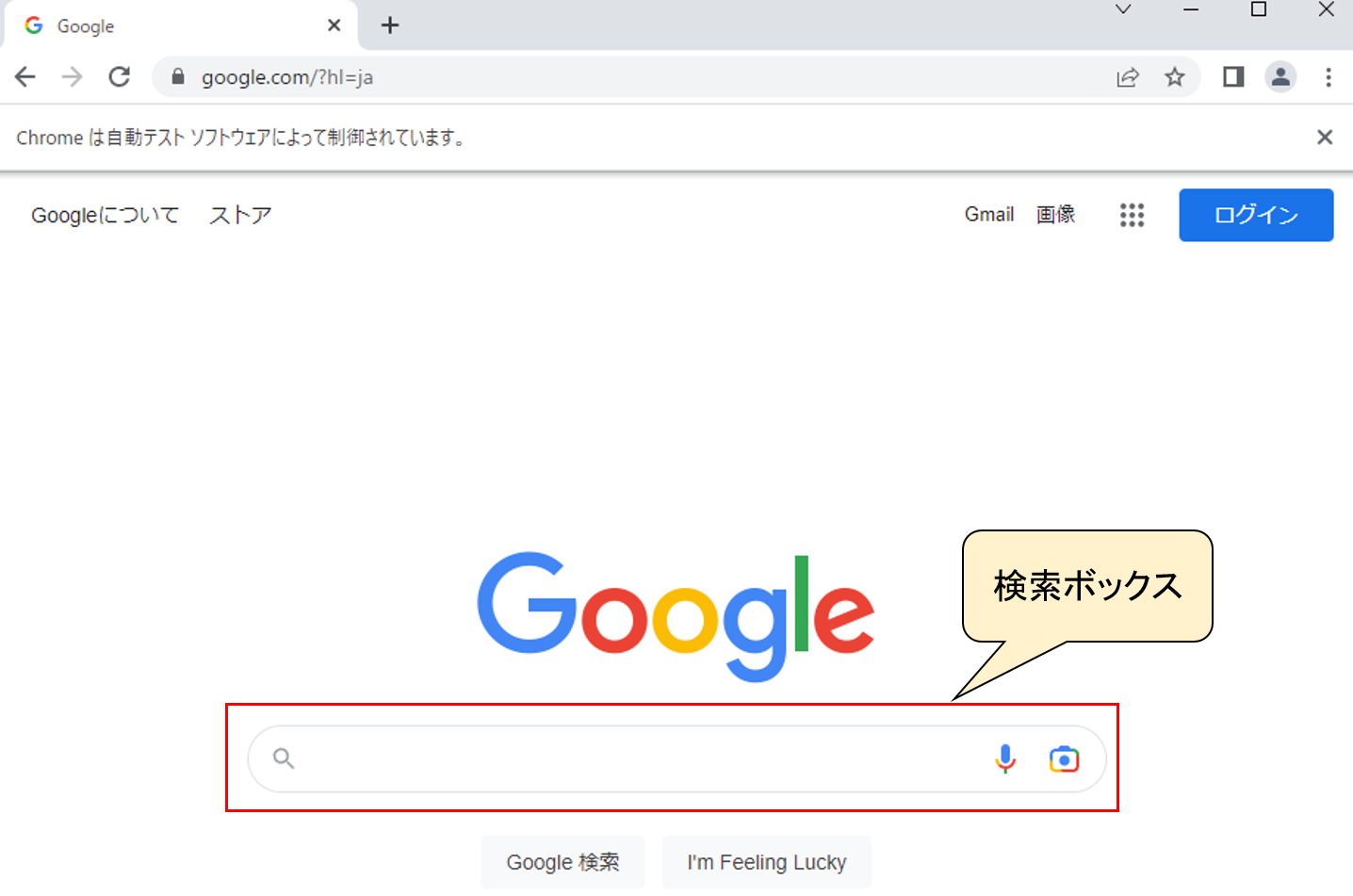
では、この検索ボックスはどうやって表されているのでしょうか。
それは、HTMLといわれる言語で表されています。
HTMLはWebページを構成するのに使われる言語になります。
HTMLでは検索ボックスは、
上図のHTMLの構成で表されています。
ここではHTMLについては深くは紹介しませんが、
Seleniumを扱う場合は、HTMLの理解もある程度必要になってきます。
検索ボックスが表されているHTMLがわかったので、
これより検索ボックスを取得してみます。
取得するには、
elem_searchBox = browser.find_element_by_name('q')
とすることで、検索ボックスを取得することができます。
ここでは、elem_searchBoxと定めた変数に、find_element_by_nameメソッドで
返ってきた結果を代入しています。
browser変数には、先ほど立ち上げたブラウザ情報が代入されています。
ちなみにbrowser変数の型としては、

となり、WebDriberのfind_element_by_nameメソッドを使用して、
検索ボックスを取得します。
find_element_by_nameメソッドに引数として、対象のWebページ内で
検索ボックスを表すタグの値を渡してあげます。
検索ボックスを構成するHTMLでは、nameというタグがありました。
また、nameというタグには”q”といった値が代入されていました。
したがって、nameタグのqと指定してやれば、検索ボックスが取得できます。
検索ボックスにキーワードを入力
取得できた検索ボックスに対して、キーワードを入力するには、
取得した要素オブジェクトのsend_keysメソッドを使用することで、
検索ボックスに対して入力ができます。
こんな風になります。
elem_searchBox.send_keys("[検索したいキーワード]")
例えば、検索したいキーワードに”今日の献立”と入力したい場合、
elem_searchBox.send_keys("今日の献立")
実行してみると、
検索ボタンの要素を取得し実行
ここまでできたら、後は実際に検索をするのみです。
検索ボックスを取得した要領で、検索ボタンを取得していきます。
ちなみに検索ボタンは、以下のようにGoogleのページでは構成されています。

同様に、find_element_by_nameメソッドを使用して、検索ボタンを取得します。
コードで表すと
elem_btnSearch = browser.find_element_by_name('btnK')
となります。
これで検索ボタンを取得することができました。
次は、取得した検索ボタンを押すにはどうしたらいいでしょうか?
これもseleniumでサポートされているメソッドである、click()メソッドを使用することで、
押すことができます。
こんな風に
elem_btnSearch.click()
実行すると
検索ボタンを押して、検索をすることができました。
さて、ここからが本題です。
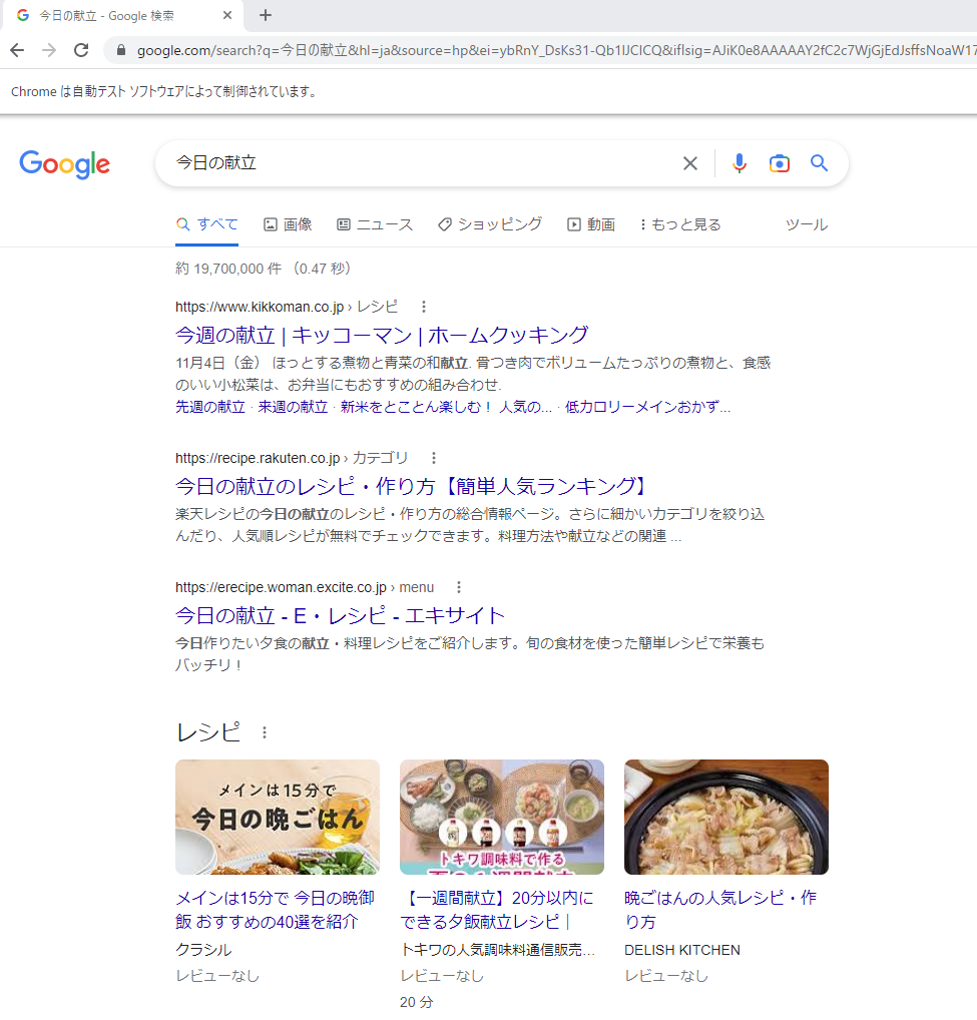
検索した結果を、取得していきたいと思います。
検索した結果をまとめて取得
1件1件の検索結果は、調べてみると、

どうやら、classタグの”MjjYud”で統一されているようです。
つまり、これを複数取得すれば、検索結果をまとめて得ることができそうです。
複数取得するには、find_elements_by_class_nameメソッドを使います。
先ほどとは違い、find_elementの後にsが付いています。
sが付くことで同名のオブジェクトを複数取得することができます。
また、class_nameでは、classタグの引数に渡された値を持つオブジェクトを
取得してくれます。
したがって、MjjYudを持つ同名のオブジェクトをまとめて取得することができます。
コードで表すと
elems_rec = browser.find_elements_by_class_name('MjjYud')
結果がいくつ収められているか確認してみます。
elems_rec = browser.find_elements_by_class_name('MjjYud')
len(elems_rec)
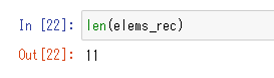
elems_recには11個のMjjYudを持つオブジェクト(検索結果)が
代入されているのがわかります。
ここまでで検索結果をまとめて、取得することができました。
最後に、ここからタイトルとページのURLを取得して、一覧を作成していきます。
検索結果のタイトルとページのURLを取得
下図におけるタイトルとURLを取得していきます。
先ほどの複数取得した結果の1つから、タイトルとページのURLを抜き出してみます。
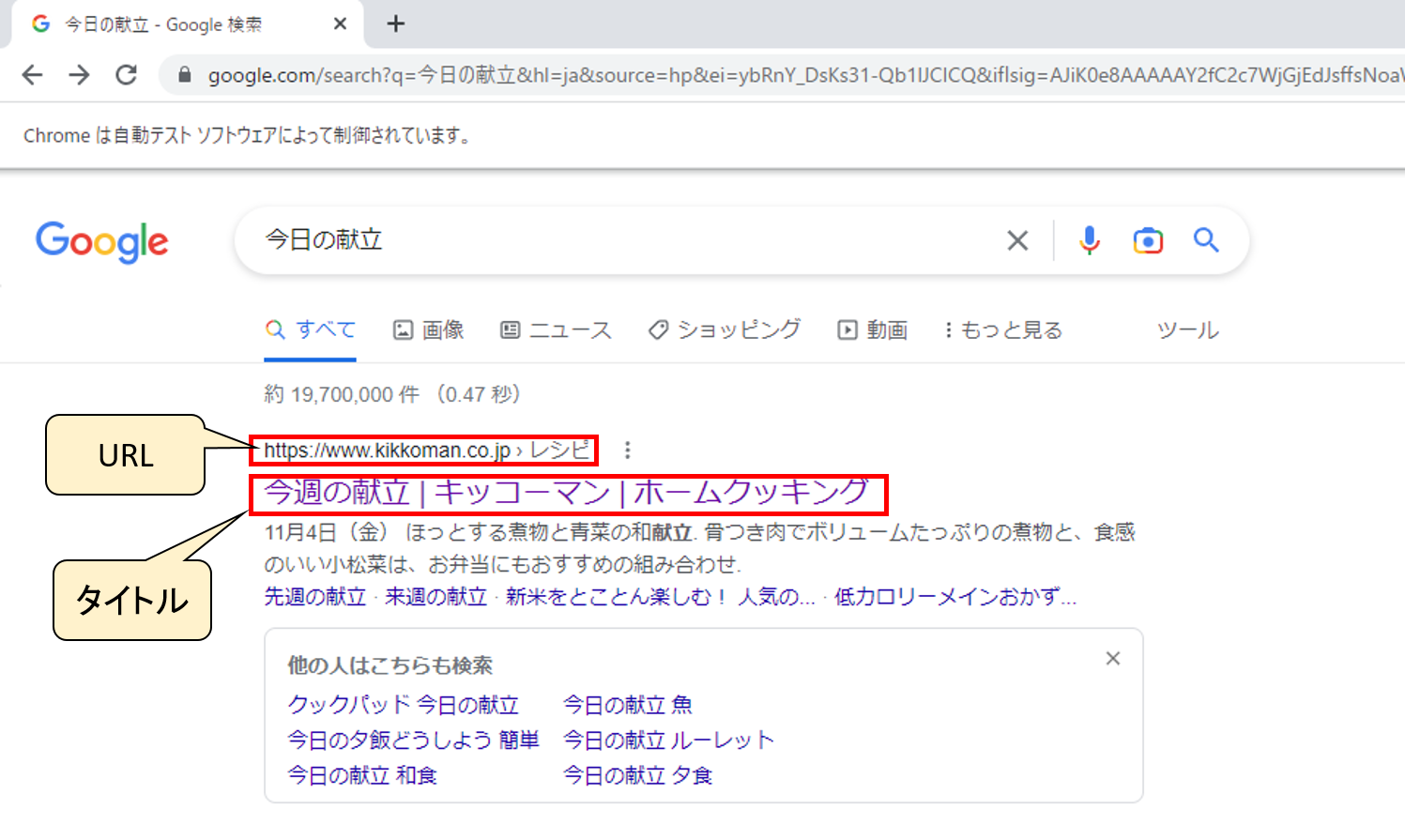
まず、タイトルについては、
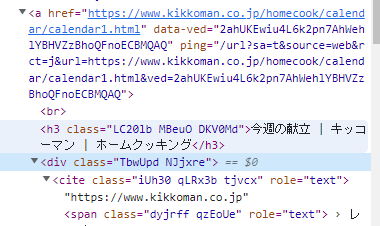
どうやら、h3タグに収められているようです。
※今回の検索では、いずれもh3タグに収められていました。
URLについては、
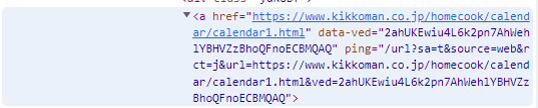
aタグのhref属性にURLが記述されているようです。
もしくは、

citeタグからもURLが取得できそうです。
タイトルもURLもいずれもHTML構成でいうとaタグの中に含まれていますね。
そのため、aタグを起点にそれぞれの情報を抽出していきます。
タイトルの取得
elem_title = elems_rec[0].find_element_by_tag_name('a').find_element_by_tag_name('h3')
URLの取得
elem_Url = elems_rec[0].find_element_by_tag_name('a').get_attribute('href')
検索結果が代入されたelems_rec変数の1番目の検索結果から、
タイトルとURLを抽出しています。
タイトルでは、aタグを起点にh3タグの情報を取得しています。
一方でURLは、aタグに含まれるhref属性の情報を取得しています。
最終的には、結果を辞書変数に代入していきます。
dictRec = {elem_title.text:elem_Url}

あとは、これをループ処理を駆使すれば、検索結果一覧が取得できます。
dictRec = {}
for elem_tag in elems_rec:
try:
elem_Url = elem_tag.find_element_by_tag_name('a').get_attribute('href')
elem_title = elem_tag.find_element_by_tag_name('a').find_element_by_tag_name('h3')
dictRec[elem_title.text] = elem_Url
except Exception as e:
continue
※一部でエラーが発生するため、try~exceptで例外をキャッチし、
ループ内を全ての検索結果が1回は処理されるようにしています。
結果は下図のようになります。

ちなみにエラーとなっていたのが、下図の赤枠の部分です。
こちらは、MjjYudは同じなのですが、以降のタグ構成が変わっており、
正しく取得ができないため、エラーとなってしまいます。
※もう少し検証が必要ですね……。
エラーは出ましたが、何とか、まとめて取得することができました。
まとめ
Python + Seleniumを活用して、Google検索した結果をまとめて取得し変数に格納しておく
方法について簡単に紹介していきました。
外部ファイルへの出力も、複数取得した検索結果から、最終的にタイトルとURLを取得した、ペアを1行ずつに落とし込めば、ファイル出力も可能です。
本記事で、Seleniumを扱う場合の工夫など参考にできる部分があると嬉しいです。
最後までお読みいただきありがとうございます。
・こちらの書籍を参考にPythonの理解を深めました。