どうも!リョクちゃです!
大変ご無沙汰しております。記事が更新できないまま、1カ月以上経過していました。
生活が激変(転職による影響)してから全然でした、、、。
とはいうものの、転職してからプログラミングする機会がなくなってしまい、
全然触れていませんでした。。。
さて、今回はSeleniumとPandasを活用してWeb上に表示されている表を取得し、
最終的にExcel形式で保存する方法について簡単に紹介していきます。
ちなみに前回はこちら


目次
Web上に表示されているテーブルデータ(表)
下図のような表をテーブルデータと、ここでは扱っています。
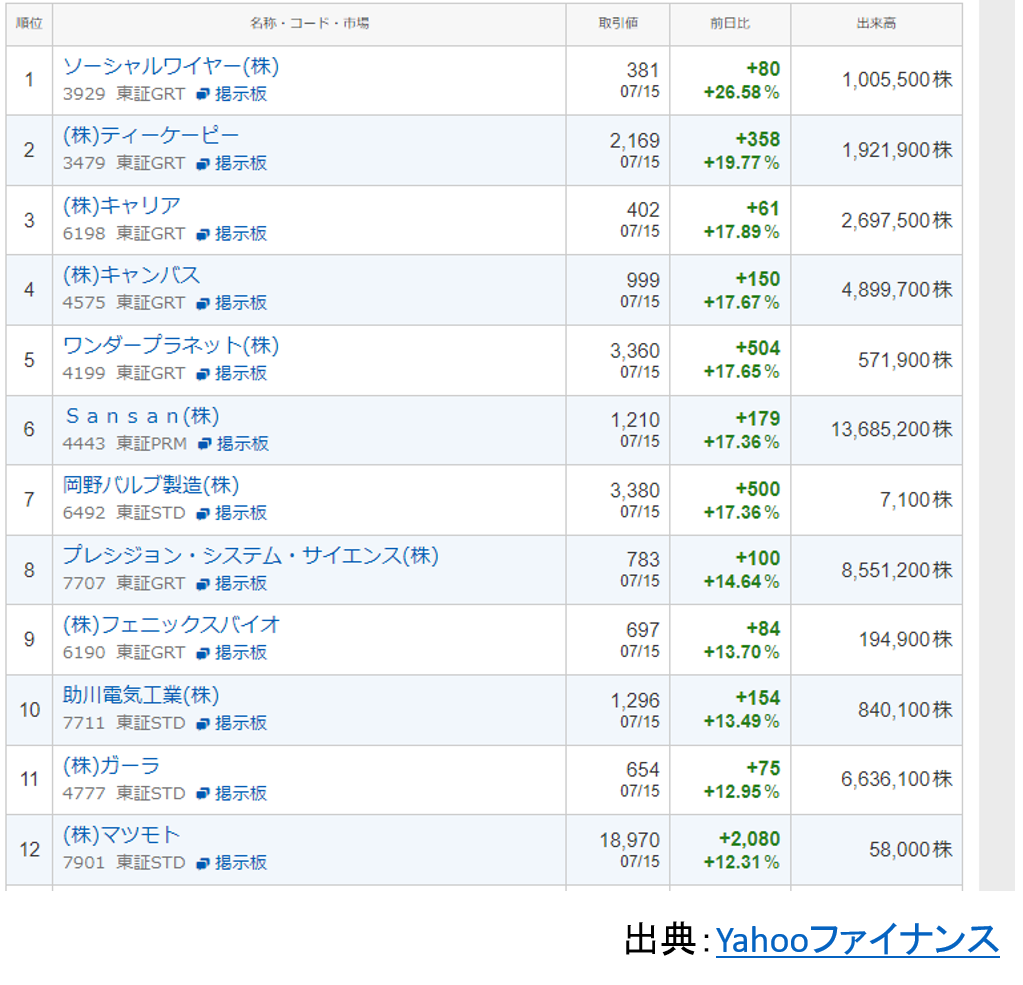
※一例として、Yahooファイナンスのページを引用しております。
Web上では、図のように表示された表をテーブルデータといいます。
今回は、これを取得して、Excel形式で保存をしていきます。
テーブルデータ取得への道
Web上の表を取得するには、ざっと下のような流れで作業を細分化できます。
① Web上で取得したい表を形成するtableタグを探し・抽出
② 抽出した情報のHTMLを取得
③ PandasでHTMLを読込み、listに変換
④ listからDataFrameへ変換
⑤ DataFrameからExcel形式に出力(保存)
①~⑤の流れを進めることで、最終的にExcel形式に出力することができちゃいます。
1つ1つ順を追って説明していきます。
※取得したい表が掲載されているURLの選定はここでは作業の流れに含んでおりません。
各々でURLは見つけてみて下さい。
Web上で取得したい表を形成するtableタグを探し・抽出
今回は、”とうもろこしの生産量ランキング(都道府県別)“のページから
都道府県別にまとめられたとうもろこしの生産量の表を取得していきます。
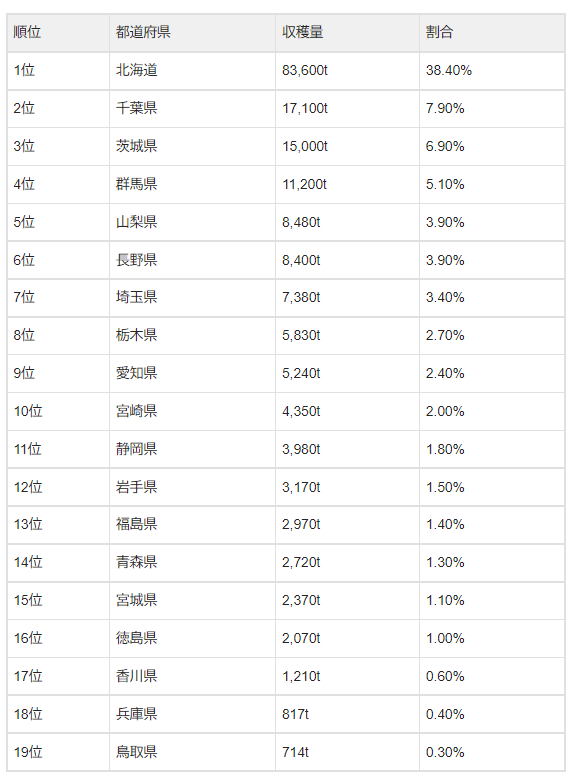
こちらの表を取得したいと思います。
まずはこの表がどんな構成でWebページ上に表示されているかを解析していきます。
ここではブラウザをChromeとして説明していきます。
Chromeで対象のURLを開き、右クリックし「検証」を押します。
下図のようなイメージになります。
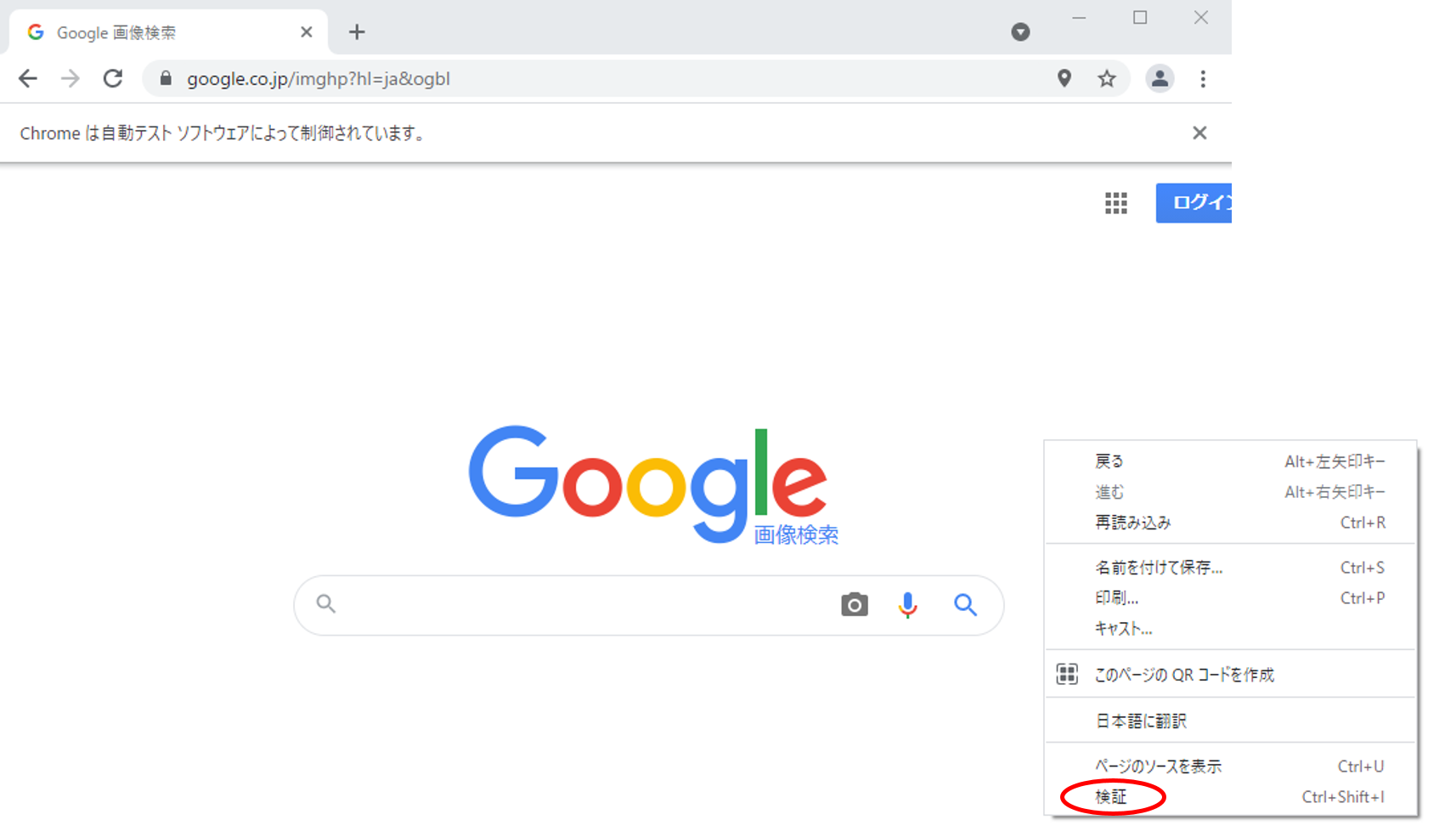
「検証」をクリックすると、ページを構成するHTMLがブラウザ上に表示されます。
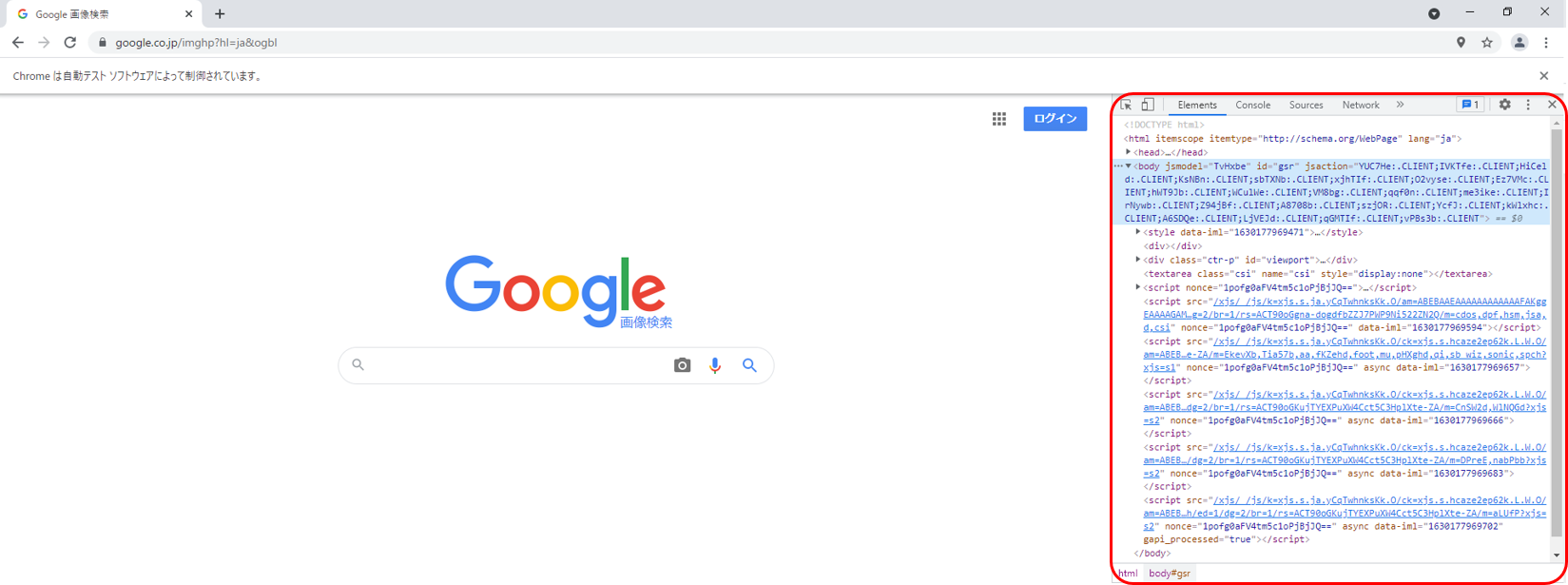
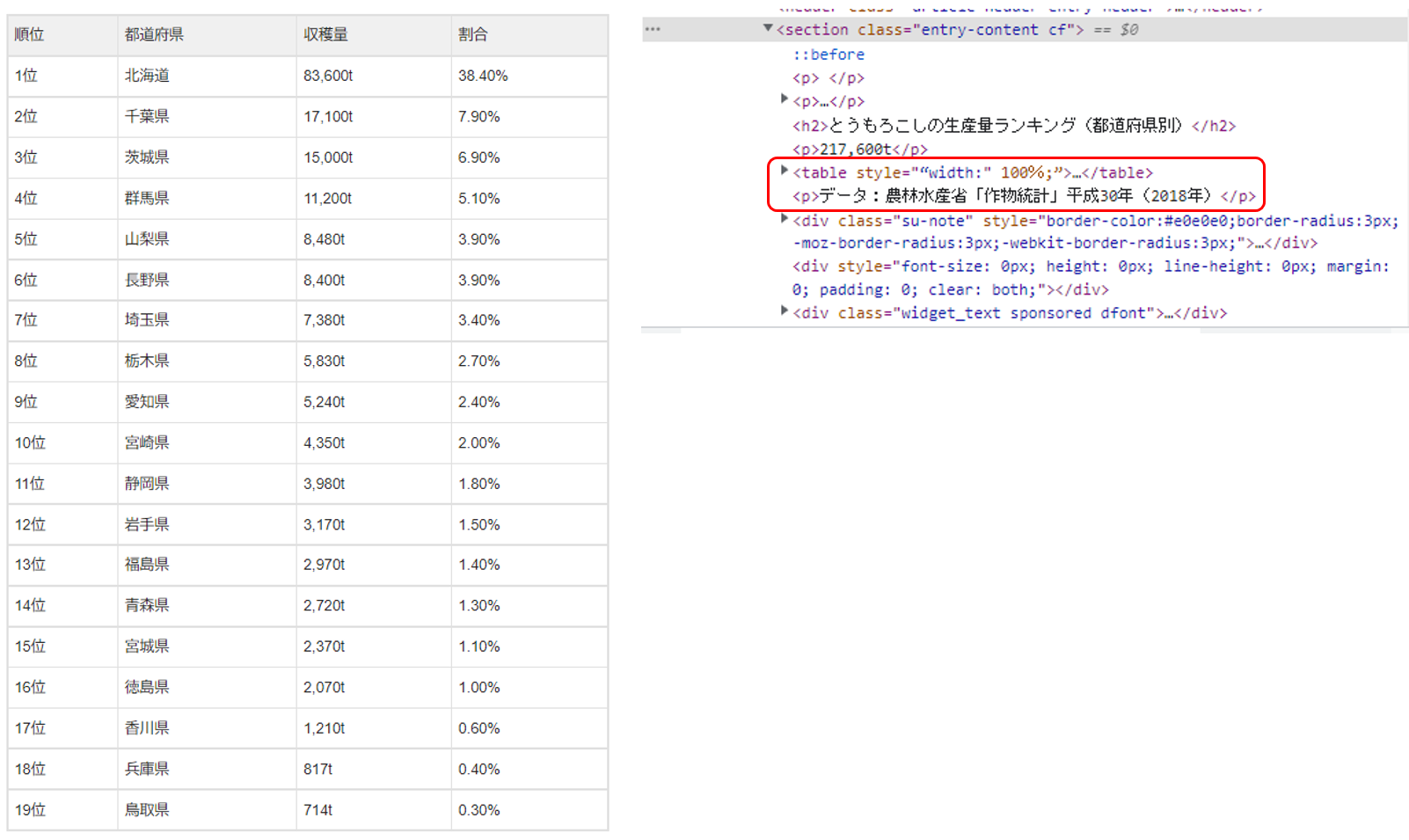
HTMLから取得したい表を形成するtableタグを探していきます。
今回取得したい”都道府県別とうもろこしの生産量”の表は、
下図に示すtableタグで表が形成されていました。
このtableタグを取得するには、tableタグ上で右クリックをし、「Copy」にカーソルを当て、
表示される項目から今回は、「Copy selector」を選びます。(下図)
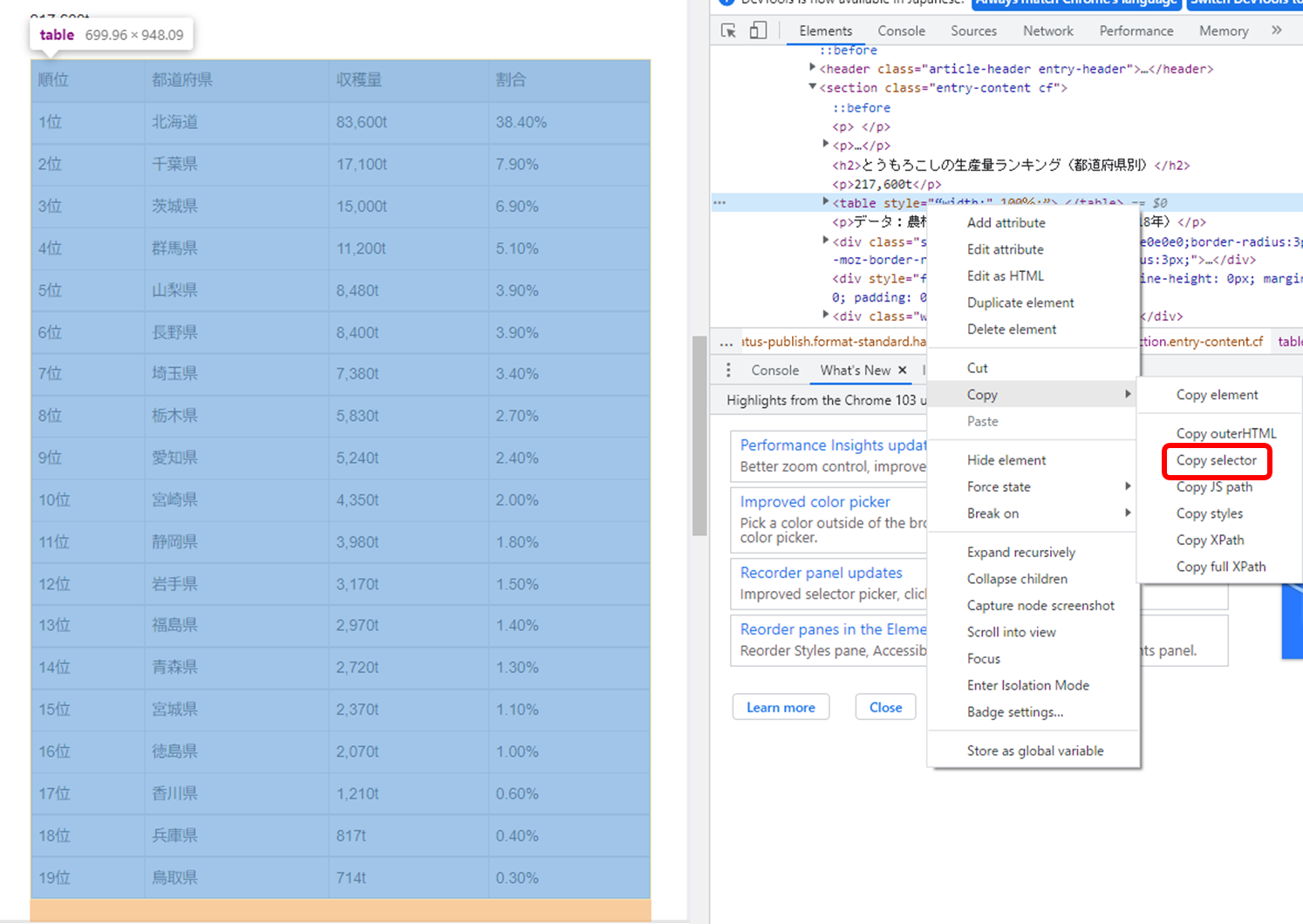
これでtableタグを取得することができました。
ここまでをSeleniumを活用してプログラムを書くと、以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from selenium import webdriver # Chromeを立ち上げる browser = webdriver.Chrome() # URLを設定 url = "https://kisetsumimiyori.com/toumorokoshiranking/" # URLを表示 browser.get(url) # 対象のURLからTable情報をゲットする elem_tableTag = browser.find_element_by_css_selector('#entry > section > table') |
抽出した情報のHTMLを取得
抽出したTableタグを含むHTML情報を取得するには、
取得したTableタグのouterHTMLプロパティを取得します。
この作業は、、、
Tableタグだけでは後続で活用するPandasでは使えないため、
outerHTMLで取得した情報を渡す必要があります。
outerHTMLプロパティを取得するには
|
1 2 |
# TableタグからouterHTMLプロパティを取得する html = elem_tableTag.get_attribute('outerHTML') |
PandasでHTMLを読込み、listに変換
次にouterHTMLの情報をPandasのread_htmlメソッドを使って、list形式に変換します。
※当初、read_htmlメソッドで変換される形式はDataFrameかと勘違いしていました。
|
1 2 3 4 5 6 7 8 |
# Tableタグから抽出したouterHTML情報をPandasでlist形式へ変換 lstTable = pd.read_html(html) # 念のため、型を確認 print(type(lstTable)) # Tableタグが取得できているか確認 print(lstTable) |
※ import Pandas as pdを忘れずに。
ここまでで、表情報の取得ができています。

listからDataFrameへ変換
ここまででExcelへ保存することをしたかったのですが、、、
list形式からExcelに出力するのがPandasで用意されているto_excelメソッドでは
できないため、DataFrameへ変換をします。
list形式からDataFrameへの変換は
|
1 2 3 4 5 |
# list形式からDataFrameへ変換 df = pd.DataFrame(data=lstTable[0]) # 念のため、型を確認 print(type(df)) |
DataFrameへ変換するには、Pandas.DataFrameメソッドを使用します。
ここでは、Pandasをインポートする際にpdと呼称しているので、
pd.DataFrameとなっています。
引数として、前述でlist形式に変換されたTable情報の0番目を渡しています。
※Web上に複数の表があれば、もしかしたらインデックスを指定して、
一度のアクセス(Seleniumからの)で好きな表を取得できると思います。
DataFrameからExcel形式に出力(保存)
最後にDataFrameからExcel形式に出力をしていきます。
ここでは、to_excelメソッドを使います。
|
1 2 |
# Excel形式で出力 df.to_excel('output_test.xlsx') |
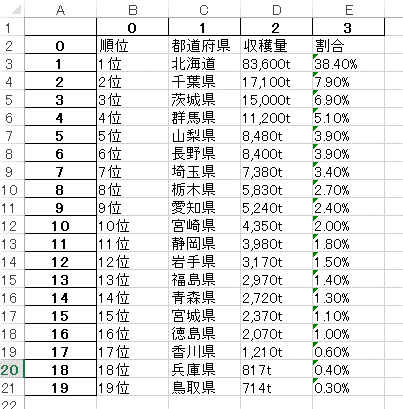
output_test.xlsxという名前でExcelファイルとして出力がされます。
下図のような形で出力がされています。
まとめ
Web上のテーブルデータ(表)をSeleniumとPandasを活用して、
Excel形式に出力する方法を簡単に紹介していきました。
SeleniumではTableタグとそれのouterHTMLプロパティを取得し、
Pandasでは取得した情報をDataFrameへと変換し、Excel形式に出力
といった作業をそれぞれ行わせています。
わざわざPandasを使わなくてもExcelへの出力はできますが、
モジュールを活用することで、コードを書く工数を削減できるため便利です。
他にもこれを応用して様々なテーブルデータを取得することができれば、
Excelに出力することも可能かと思います。
※Tableタグがあるもの
参考になれば嬉しいです。色々活用していただけたらと思います。
最後までお読みいただき、ありがとうございます。
これからも継続して書きつづっていきます。
よろしくお願いします!
・こちらの書籍を参考にPythonの理解を深めました。

