どうも!リョクちゃです。
今回はGoogle検索でヒットした画像を取得するといった作業(動作)を、
Seleniumを使って自動化してみる方法を紹介していきます。
ちなみに前回の記事はこちら


ここでは既にPythonとSeleniumがインストールできている状態として話を進めていきます。
インストールがまだの方は、インストールをしておいていただければ嬉しいです。
以下の記事でインストール方法についても触れています。


動作環境
筆者の環境は、Python 3.6.1になります。
古いですね……。
Seleniumのバージョンは、3.141.0になります。
Seleniumのインポート
まず最初にSeleniumのインポート(使う準備)をします。
GoogleChromeブラウザを起動
URLを開く
今回は画像の検索をGoogleで行うので、以下のURLをブラウザ上で開きます。


URLを開くには、
と書きます。
実際にURLを当てはめると、
browser.get(‘https://www.google.co.jp/imghp?hl=ja&ogbl‘)
となり、実行すると
画像の検索を行う
ここからは取得する画像の検索を行います。
今回は猫の画像を取得し、検索することとします。
画像を検索するにあたって、
まずは開いたページの構成がどうなっているのか理解する必要があります。
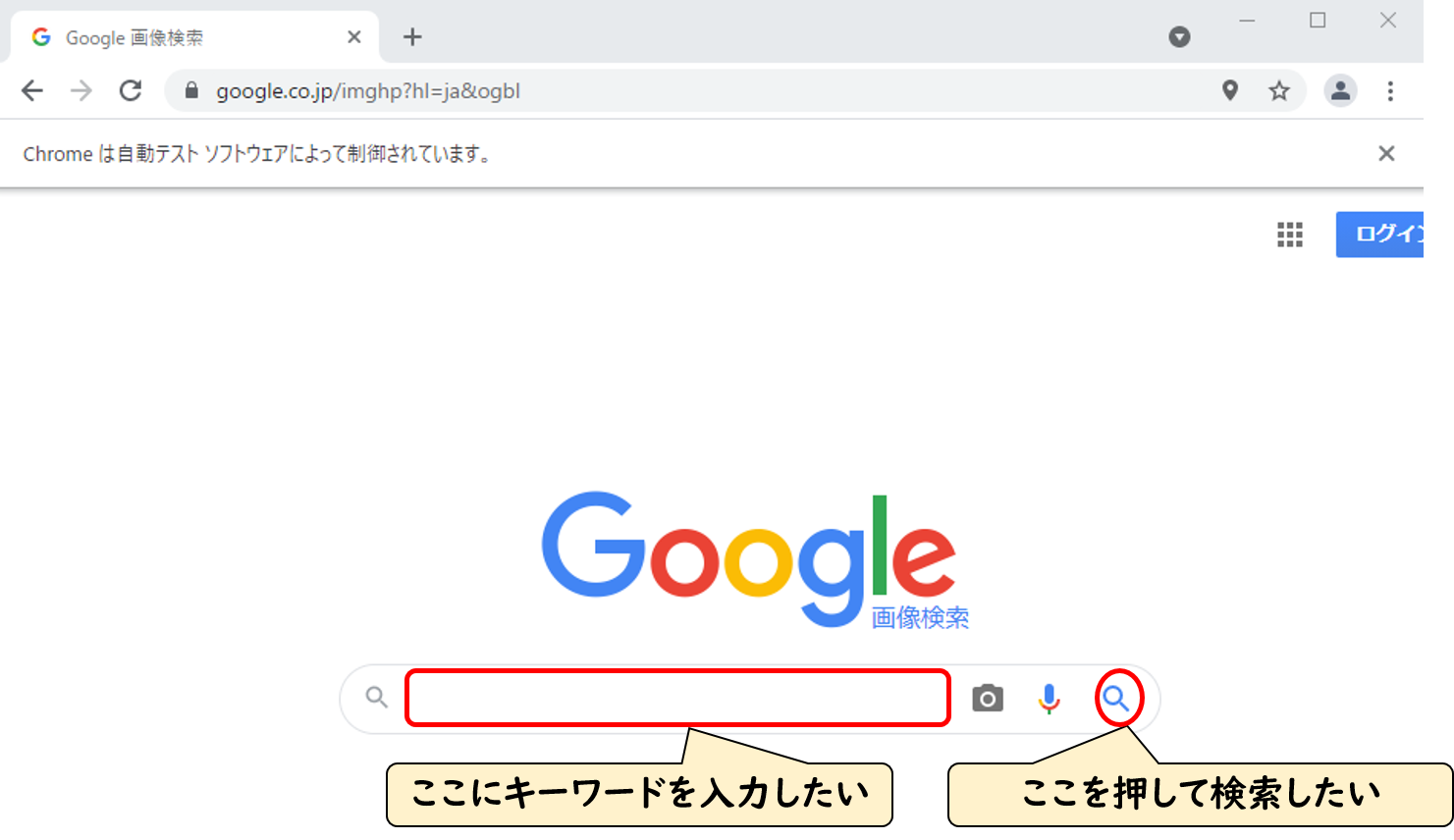
今回は、下図の赤枠で囲われた部分を使って検索をしたいので……
これには以下の手順でページを構成する要素を調べていきます。
- 開いたWebページの”検証”を行う。
- 検証タブの”Select an element ~”をクリックする。
- カーソルを調べたい要素に合わせる。
- 要素のxpathをコピーする。
といった流れで要素の検出を行います。
ここでいう”要素”とは、ページ上の見出し、ボタンや段落などを指します。
詳細に言うと、WebページはHTMLと呼ばれる、
マークアップ言語で書かれたファイルに基づき、構成がされています。
いわゆるhtmlファイルと呼ばれるものになります。これがWebページの顔となります。
Webページは、主に下図のような感じで構成されています。

※あくまで一例です。だいたいはもっと多くのコードが書かれていたりします。
これはただ単に”Hello World”と表示されているだけのページになります。
例のように、や
などが要素を表します。
だと見出し1になります。
ブラウザを操作する上では、このHTMLの各要素を知ることから始まります。
今回では、検索ボックスと検索ボタン(虫眼鏡アイコン)の要素を知ることになります。
これらを知るには、ページ内で右クリックを押し、検証ボタンを押します。
※GoogleChromeの場合、各ブラウザで違います。
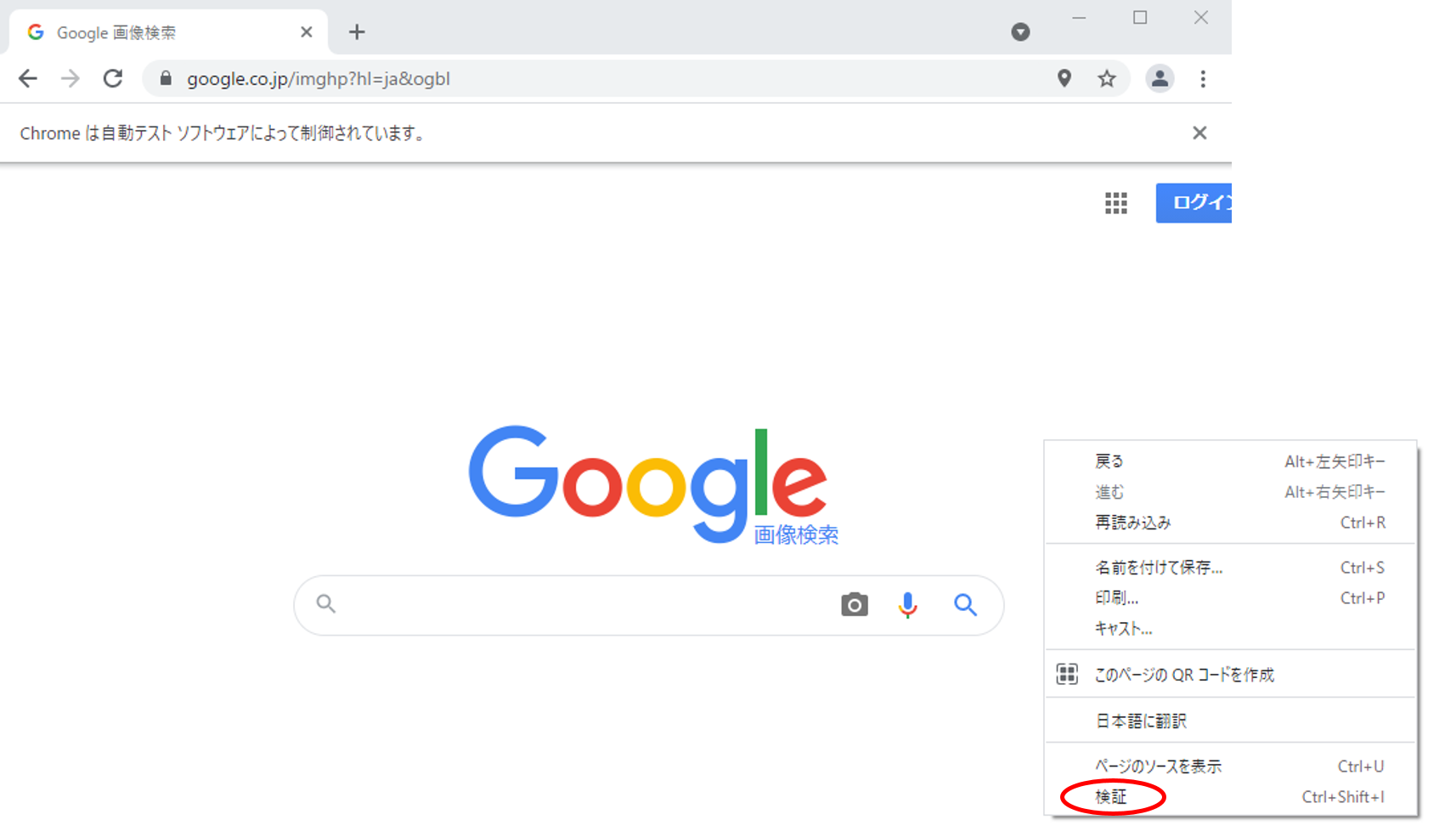
検証ボタンを押すと、
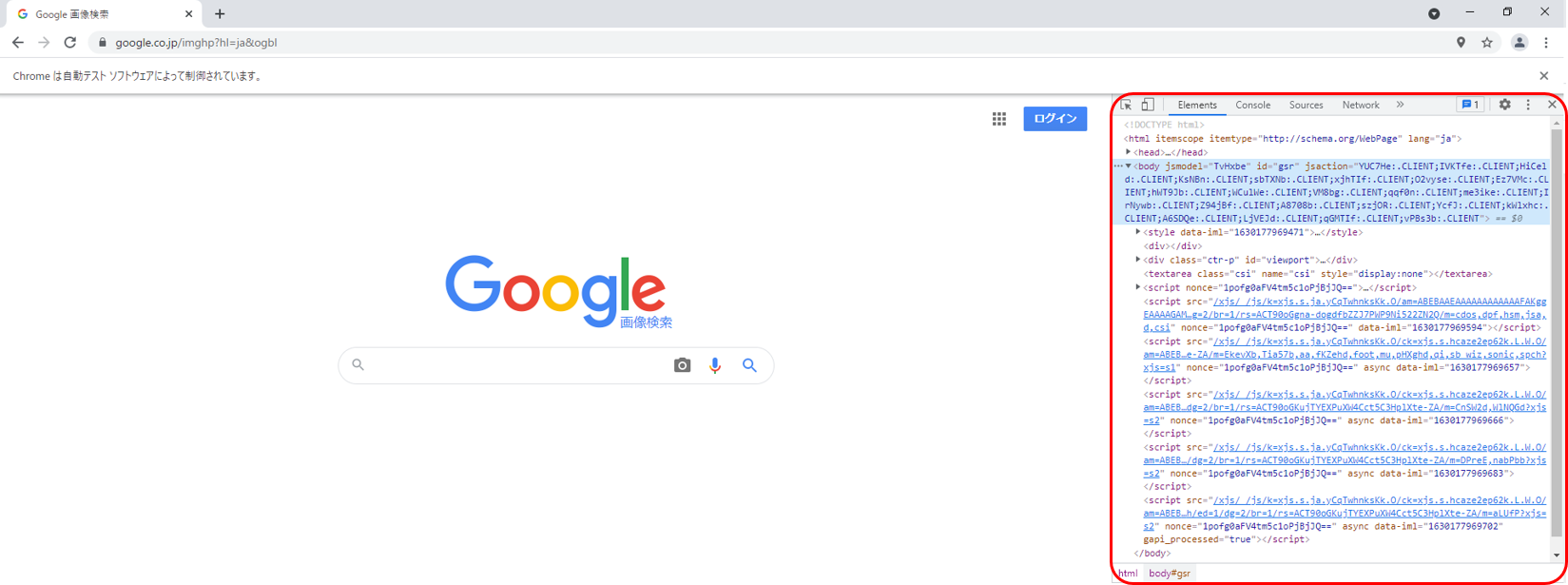
赤枠で囲まれた部分が展開されます。(検証タブと呼ぶことにします。)
これが現在開いているページを構成する中身になります。
いろいろとコードが書かれていますね。
これを元に要素の検索をしていきます。
検索をするには、
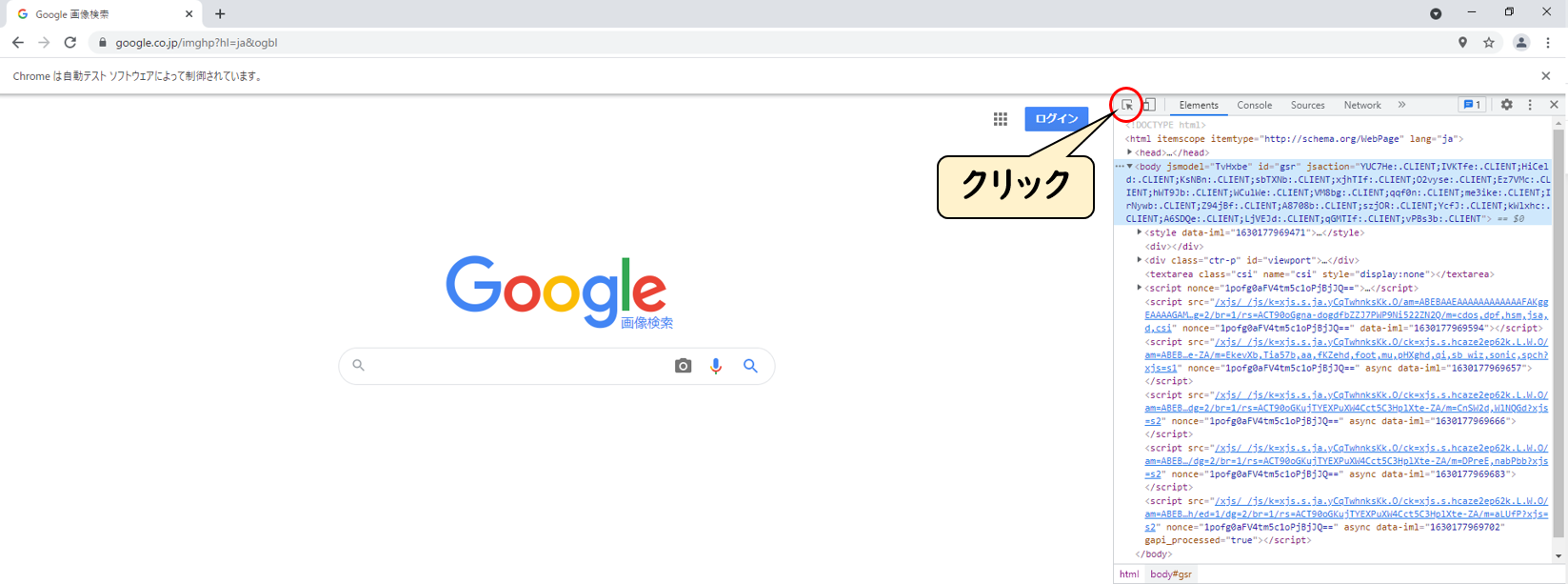
赤丸で囲んだ矢印アイコンをクリックします。
クリックした状態で、カーソルを検索ボックスと検索ボタンに合わせます。
※合わせるだけでクリックは、まだしません。
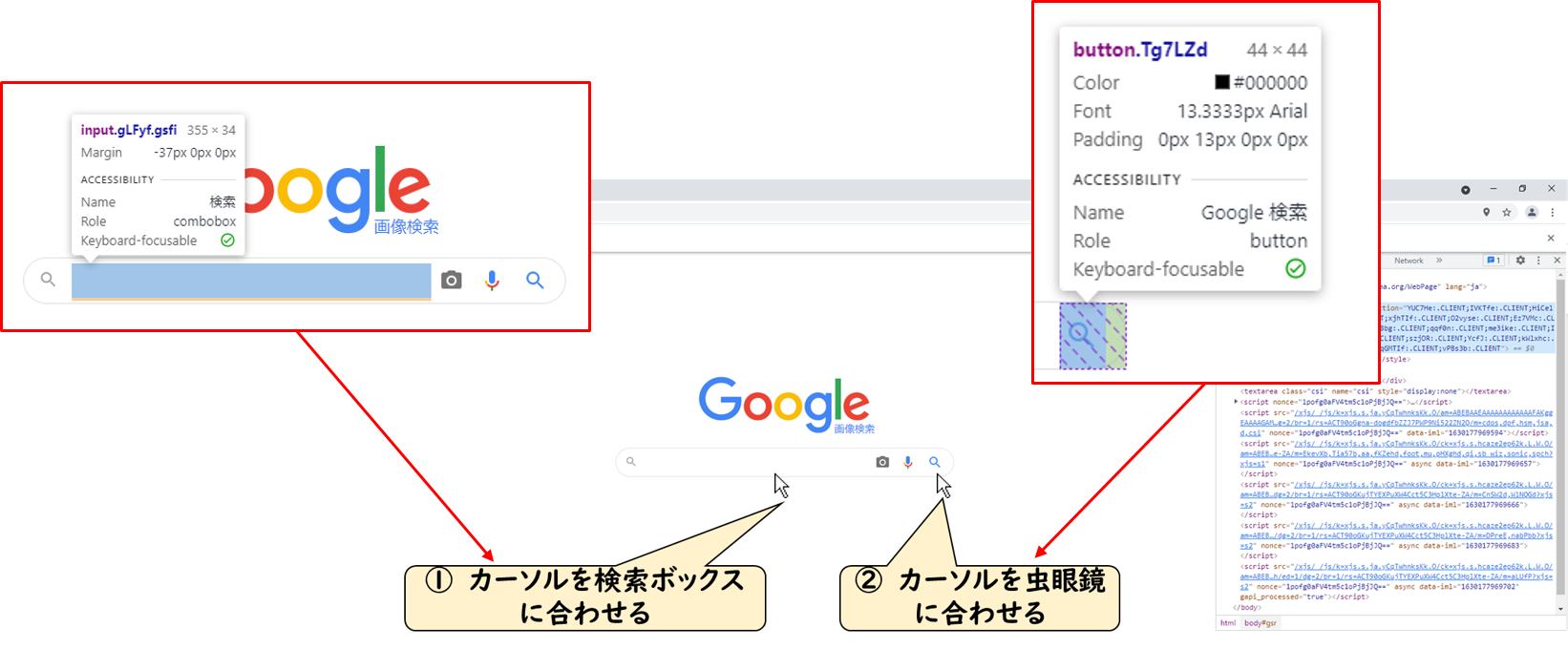
カーソルを合わせると、青く選択され、その上にパラメータが表示されるかと思います。
このパラメータが、それぞれの要素となります。
ここからさらに調査をし、どの位置(場所)に要素があるのか掴んでいきます。
楽しくなってきましたね。
ここで検索ボックスの要素の場所を取得していきます。
検索ボックスにカーソルを合わせた状態でクリックをします。
すると、この要素がどこにあるのか検証タブ内で教えてくれます。
※検証タブ内で青く選択される場所になります。
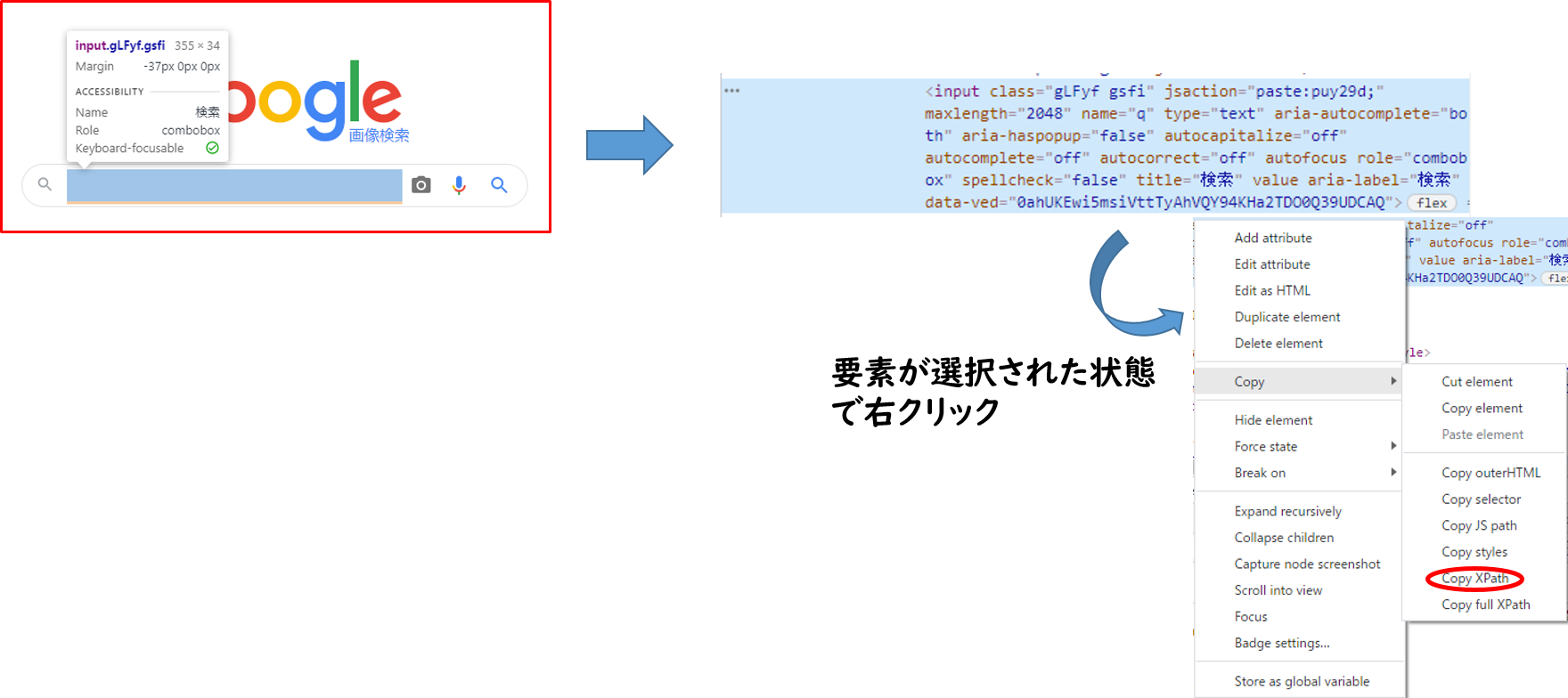
青く選択されたら、右クリックをします。
ウィンドウが開くので、Copyを押し、Copy xPathを押します。
下の図のような感じです。
xPathとは、XML Path Languageの略になります。
HTMLドキュメントからの要素や属性値などを指定するための簡潔な言語となっています。
覚えておくと便利です。
実際に検索ボックスをコピーしたxpathは、こちらになります。
//*[@id=”sbtc”]/div/div[2]/input
同様に、検索ボタンもxpathをコピーすると、
//*[@id=”sbtc”]/button
となります。
これを使って、実際に検索ボックスにはキーワードの入力、
検索ボタンでは押下するといった各動作を行わせていきます。
まずは、各変数を作成し、検索ボックスと検索ボタンの要素を代入しておきます。
要素の抽出には、
browser.find_element_by_xpath(‘取得する要素のxpath’)
と書きます。
検索ボックス
1
elem_keyword = browser.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
検索ボタン
1
elem_button = browser.find_element_by_xpath('//*[@id="sbtc"]/button')
各変数に要素を収めることができました。
検索ボックスにキーワードを入力するには、
.send_keys(‘検索したいワード’)
と書きます。
今回だと、
elem_keyword.send_keys(‘猫’)
となります。
これを実行すると、
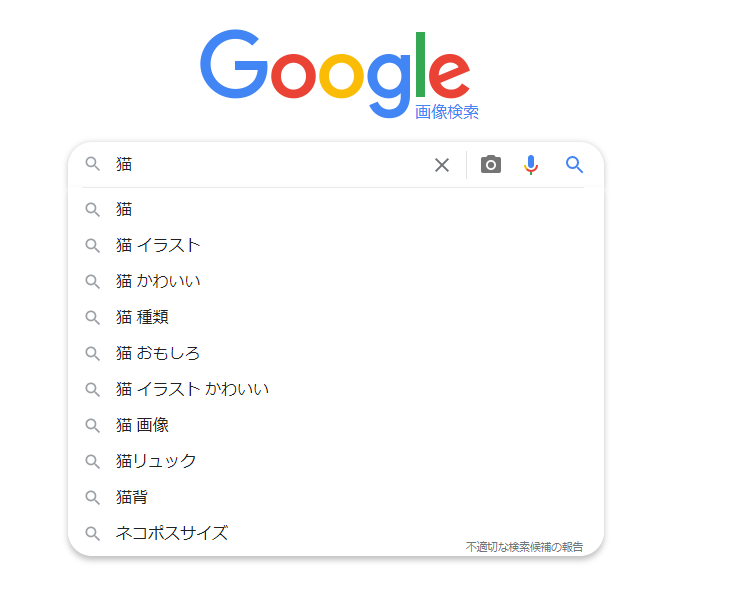
入力されているのがわかります。
次いで、検索ボタンを押下していきます。
押下するには、
.click()
と書きます。
今回だと、
elem_button.click()
となります。
これを実行すると、
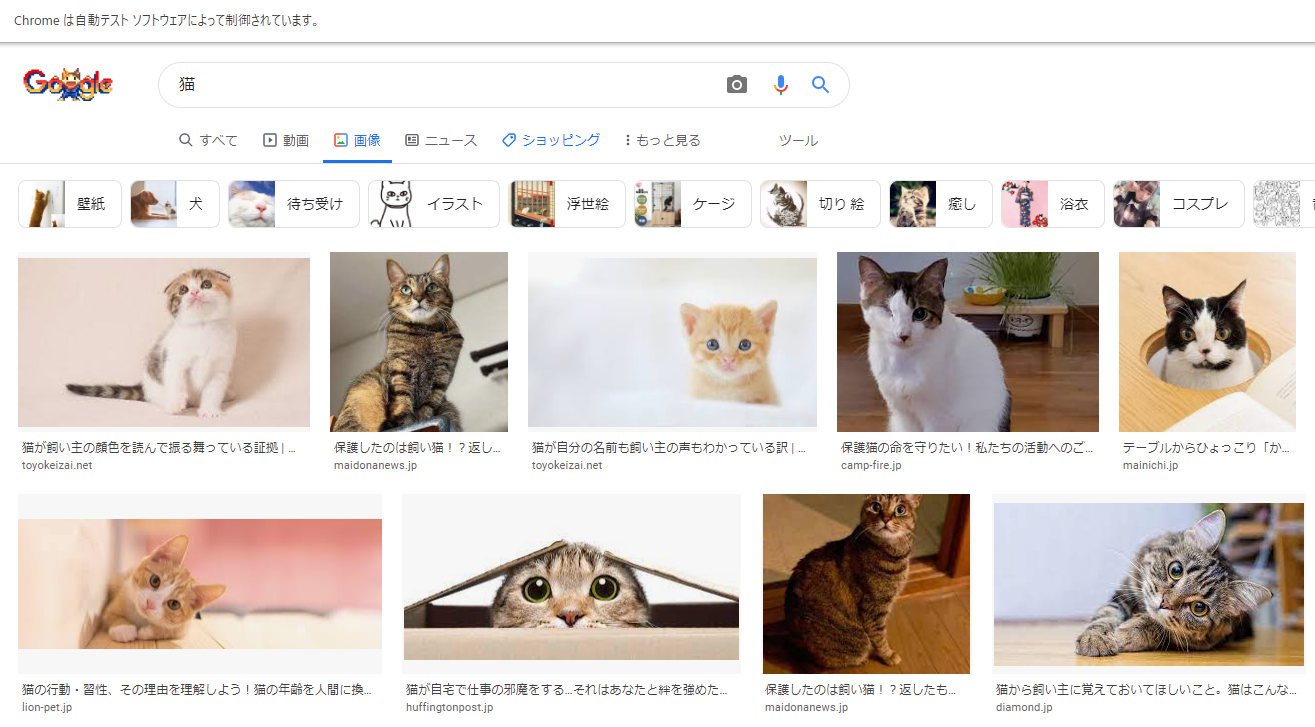
画面が切り替わり、猫の画像が表示されるようになりました。
これで検索ができるようになりました。
ここまでで要素を取得し、検索ボックスへの入力、
検索ボタンの押下ができるようになりました。
以降は、実際に画像の取得をしていきます。


検索できた結果から1枚目の画像を取得していきます。
まずは1枚目のサムネイルの画像のリンクを取得します。
リンクを取得するには、
1
elem_pic = browser.find_element_by_xpath('//*[@id="islrg"]/div[1]/div[1]/a[1]/div[1]/img')
とします。
上述した取得したい要素のxpathを取得し、変数に要素を代入しています。
取得したリンクをクリックします。
1
elem_pic.click()
実行すると、
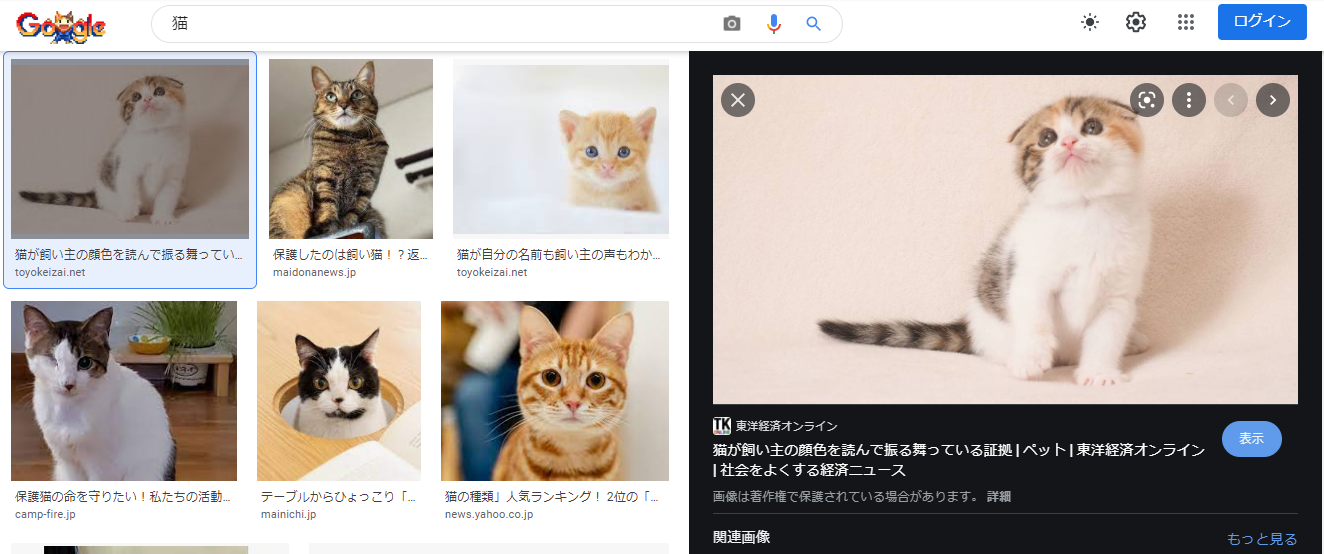
1枚目の画像のサムネイルをクリックした状態です。
サムネイルの画像のURLを取得
クリックしたサムネイルの画像を取得するためには、画像のURLを取得する必要があります。
画像のURLを取得するには、まずは要素の検出を行い、xpathを見つけます。
サムネイルの画像のxpathは
//*[@id=”Sva75c”]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img
となることがわかりました。
この要素を変数に代入していきます。
1
elem_imgUrl = browser.find_element_by_xpath('//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img')
これだけでは画像のURLを取得することができないので、
さらに要素内のURLを格納している属性まで絞り込みます。
調べてみると画像のURLの属性は、”src”と呼ばれる属性に格納されているようです。
つまりはsrc属性を取得すれば、画像のURLを取得することができます。
src属性を取得するには、
.get_attribute(‘取得したい属性’)
と書きます。
今回だと、
elem_imgUrl.get_attribute(‘src’)
これを変数に代入しておきます。
1
img_url = elem_imgUrl.get_attribute('src')
変数の中身をのぞいてみると、
https://tk.ismcdn.jp/mwimgs/7/6/1140/img_761783d94524387445e94d79e99b739a80657.jpg
見事に画像のURLを取得することができました。
画像を読込む
取得した画像のURLから画像を読み込んでみます。
画像を読み込むには、新たにrequestsライブラリと
ioライブラリ、PILライブラリをそれぞれインポートします。
requestsライブラリ
これはHTTP通信用のライブラリで、HTMLファイルからデータを取得するのに使われます。
ioライブラリ
ストリームを扱うコアツール
で今回は、バイナリIOとして扱います。
画像データをメモリ上でバイトデータで読取るために使用します。
こちらは標準でインストールされています。
PILライブラリ(=Pillow)
画像処理用のライブラリで、画像の表示と保存に今回使います。
インストールされていない場合は、
pip install requests
pip install Pillow
でインストールができます。
インポートは、
import requests
import io
from PIL import Image
まずは画像のURLから画像データのバイト列を取得していきます。
取得するには、
requests.get(‘画像のURL’).content
今回だと、
requests.get(img_url).content
となり、これも変数に代入しておきます。
1
img = requests.get(img_url).content
次に、BytesIOを使って、画像を読み込みます。
io.BytesIO(画像データ)
今回だと、
1
img_file = io.BytesIO(img)
とし、変数に代入しておきます。
いよいよ、取得した画像データをPILライブラリを使って表示させていきます。
表示させるには、
Image.open(“画像ファイル”)
今回だと、
img_rec = Image.open(img_file)
とし、読み込んだ画像を変数に入れておきます。
実行すると、



画像の保存
画像も表示できたので、最後に保存をしていきます。
画像の保存をするには、
.save(‘画像ファイルの保存先+ファイル名’)
とすることで保存が行えます。
今回だと、
1
img_rec.save('imgCat01.jpg')
と書きます。
ファイル名のみの場合、
現在プログラムが実行されている場所(カレントフォルダ)に保存がされます。
これで画像の保存ができました。
ここまでで画像の検索から取得、表示、保存を行ってきました。
お疲れ様でした。
まとめ
今回は、Seleniumを使って実際にGoogle検索してヒットした画像を取得し、
保存する方法について紹介しました。
この方法を応用することで複数の画像を取得出来たり、
他にも動画の取得にも活かすことができるようになるかと思います。
ただし、一度に大量の画像を間隔なしに取得するのは、
サーバに負荷がかかるのでやめましょう。
最後までお読みいただきありがとうございます。
・こちらの書籍を参考にPythonの理解を深めました。
ブラウザを操作する上では、このHTMLの各要素を知ることから始まります。
今回では、検索ボックスと検索ボタン(虫眼鏡アイコン)の要素を知ることになります。
これらを知るには、ページ内で右クリックを押し、検証ボタンを押します。
※GoogleChromeの場合、各ブラウザで違います。
検証ボタンを押すと、
赤枠で囲まれた部分が展開されます。(検証タブと呼ぶことにします。)
これが現在開いているページを構成する中身になります。
いろいろとコードが書かれていますね。
これを元に要素の検索をしていきます。
検索をするには、
赤丸で囲んだ矢印アイコンをクリックします。
クリックした状態で、カーソルを検索ボックスと検索ボタンに合わせます。
※合わせるだけでクリックは、まだしません。
カーソルを合わせると、青く選択され、その上にパラメータが表示されるかと思います。
このパラメータが、それぞれの要素となります。
ここからさらに調査をし、どの位置(場所)に要素があるのか掴んでいきます。
楽しくなってきましたね。
ここで検索ボックスの要素の場所を取得していきます。
検索ボックスにカーソルを合わせた状態でクリックをします。
すると、この要素がどこにあるのか検証タブ内で教えてくれます。
※検証タブ内で青く選択される場所になります。
青く選択されたら、右クリックをします。
ウィンドウが開くので、Copyを押し、Copy xPathを押します。
下の図のような感じです。
xPathとは、XML Path Languageの略になります。
HTMLドキュメントからの要素や属性値などを指定するための簡潔な言語となっています。
覚えておくと便利です。
実際に検索ボックスをコピーしたxpathは、こちらになります。
同様に、検索ボタンもxpathをコピーすると、
|
1 |
elem_keyword = browser.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input') |
|
1 |
elem_button = browser.find_element_by_xpath('//*[@id="sbtc"]/button') |
各変数に要素を収めることができました。
検索ボックスにキーワードを入力するには、
と書きます。
今回だと、
となります。
これを実行すると、
入力されているのがわかります。
次いで、検索ボタンを押下していきます。
押下するには、
と書きます。
今回だと、
となります。
これを実行すると、
画面が切り替わり、猫の画像が表示されるようになりました。
これで検索ができるようになりました。
ここまでで要素を取得し、検索ボックスへの入力、
検索ボタンの押下ができるようになりました。
以降は、実際に画像の取得をしていきます。
検索できた結果から1枚目の画像を取得していきます。
まずは1枚目のサムネイルの画像のリンクを取得します。
リンクを取得するには、
|
1 |
elem_pic = browser.find_element_by_xpath('//*[@id="islrg"]/div[1]/div[1]/a[1]/div[1]/img') |
とします。
上述した取得したい要素のxpathを取得し、変数に要素を代入しています。
取得したリンクをクリックします。
|
1 |
elem_pic.click() |
実行すると、
1枚目の画像のサムネイルをクリックした状態です。
サムネイルの画像のURLを取得
クリックしたサムネイルの画像を取得するためには、画像のURLを取得する必要があります。
画像のURLを取得するには、まずは要素の検出を行い、xpathを見つけます。
サムネイルの画像のxpathは
//*[@id=”Sva75c”]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img
となることがわかりました。
この要素を変数に代入していきます。
|
1 |
elem_imgUrl = browser.find_element_by_xpath('//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img') |
これだけでは画像のURLを取得することができないので、
さらに要素内のURLを格納している属性まで絞り込みます。
調べてみると画像のURLの属性は、”src”と呼ばれる属性に格納されているようです。
つまりはsrc属性を取得すれば、画像のURLを取得することができます。
src属性を取得するには、
と書きます。
今回だと、
これを変数に代入しておきます。
|
1 |
img_url = elem_imgUrl.get_attribute('src') |
変数の中身をのぞいてみると、
https://tk.ismcdn.jp/mwimgs/7/6/1140/img_761783d94524387445e94d79e99b739a80657.jpg
{kind=link}
見事に画像のURLを取得することができました。
画像を読込む
取得した画像のURLから画像を読み込んでみます。
画像を読み込むには、新たにrequestsライブラリと
ioライブラリ、PILライブラリをそれぞれインポートします。
requestsライブラリ
これはHTTP通信用のライブラリで、HTMLファイルからデータを取得するのに使われます。
ioライブラリ
ストリームを扱うコアツール
で今回は、バイナリIOとして扱います。
画像データをメモリ上でバイトデータで読取るために使用します。
こちらは標準でインストールされています。
PILライブラリ(=Pillow)
画像処理用のライブラリで、画像の表示と保存に今回使います。
インストールされていない場合は、
でインストールができます。
インポートは、
まずは画像のURLから画像データのバイト列を取得していきます。
取得するには、
今回だと、
となり、これも変数に代入しておきます。
|
1 |
img = requests.get(img_url).content |
次に、BytesIOを使って、画像を読み込みます。
今回だと、
|
1 |
img_file = io.BytesIO(img) |
とし、変数に代入しておきます。
いよいよ、取得した画像データをPILライブラリを使って表示させていきます。
表示させるには、
今回だと、
画像の保存
画像も表示できたので、最後に保存をしていきます。
画像の保存をするには、
とすることで保存が行えます。
今回だと、
|
1 |
img_rec.save('imgCat01.jpg') |
と書きます。
ファイル名のみの場合、
現在プログラムが実行されている場所(カレントフォルダ)に保存がされます。
これで画像の保存ができました。
ここまでで画像の検索から取得、表示、保存を行ってきました。
お疲れ様でした。
まとめ
今回は、Seleniumを使って実際にGoogle検索してヒットした画像を取得し、
保存する方法について紹介しました。
この方法を応用することで複数の画像を取得出来たり、
他にも動画の取得にも活かすことができるようになるかと思います。
ただし、一度に大量の画像を間隔なしに取得するのは、
サーバに負荷がかかるのでやめましょう。
最後までお読みいただきありがとうございます。
・こちらの書籍を参考にPythonの理解を深めました。